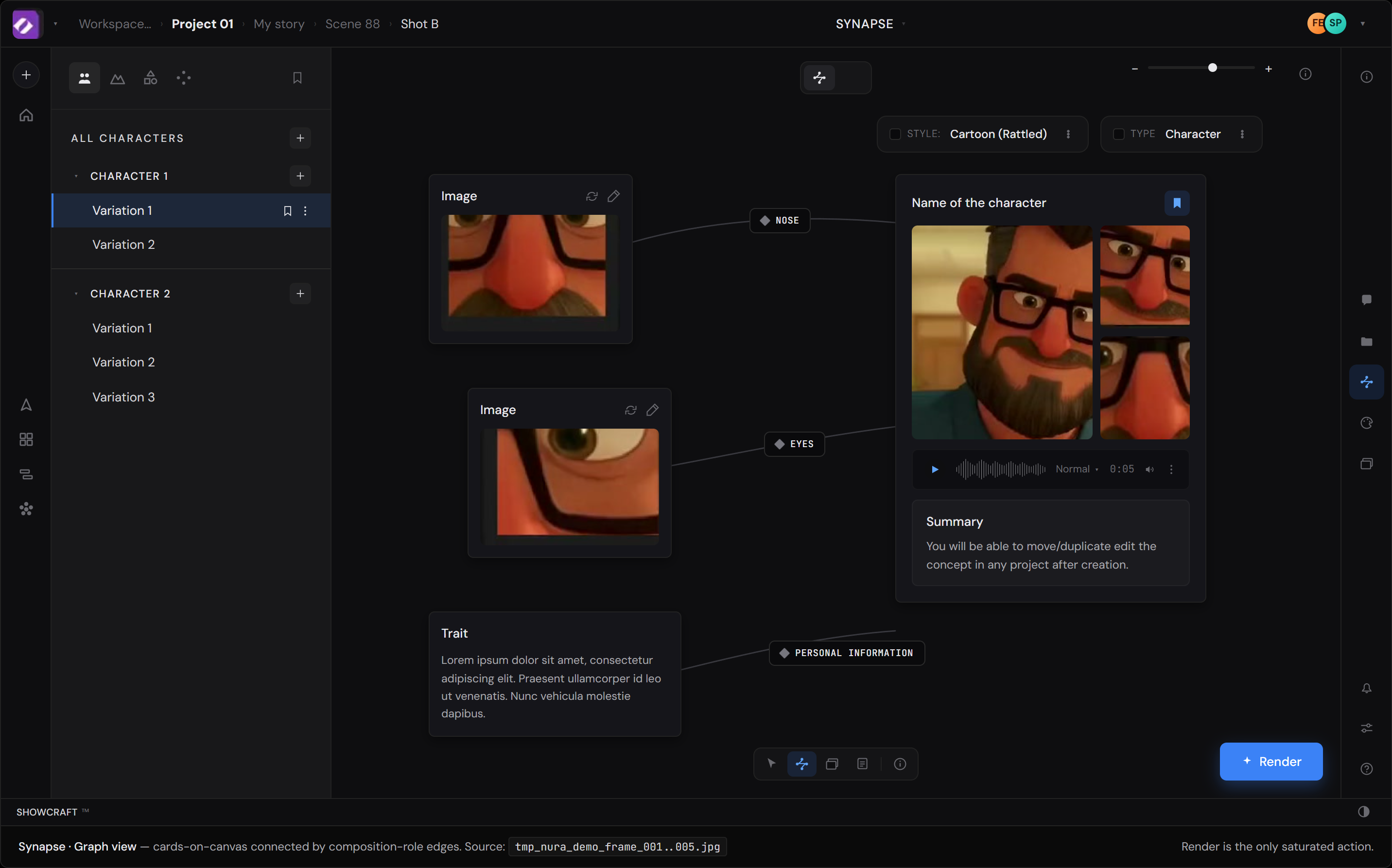
From the demo, Synapse reads to me as an asset / primitive maker; a node graph for the things storyboard is built from. Characters, environments, shapes, and at least one more thing in the dock I haven't pinned down. If I'm reading it right, the three modes aren't co-equal lenses on the same object; they're pipeline stages. Correct me if I'm off.
If that's roughly the shape, Synapse is the most upstream of the three; the least developed in what I saw. The two notes below apply to all three modes, but Synapse is where they'd land first, because everything downstream is built on what comes out of it.
Both notes extend a principle Synapse appears to already embody at the asset layer: making context explicit, named, and editable rather than implicit.
Flagging openly: this is my read from one demo loop, not a confident map of your product. The specific design moves for Synapse itself aren't earned yet by what I've seen; worth a longer conversation when there's time.